
Table of Contents
ToggleIf you’ve ever wondered how your website appears in search engine results or why certain pages seem to get more traffic, understanding website crawlability is key. So, what exactly is crawlability, and why should you care?
Crawlability is essentially the ability of search engine bots to discover and index your site’s pages. Without proper crawlability, your website might not show up in search results, no matter how great your content is.
Let’s dive into how you can ensure your site is easily crawlable and improve your online visibility.
What is a Web Crawler?
A web crawler, also known as a spider or bot, is a tool used by search engines to scan and index web pages. These crawlers follow links and gather data about your site to help determine how it should be ranked.
How Do Search Engines Crawl Websites?
Search engines use automated programs to navigate the web, starting from a list of known URLs and following links to discover new pages. They analyze the content and structure of these pages to index them for search results.
Make Sure Your Website is Being Crawled!
Improve your website’s crawlability with Go SEO Monkey.
Basic Steps to Improve Website Visibility
Ensure Your Site is Accessible to Crawlers
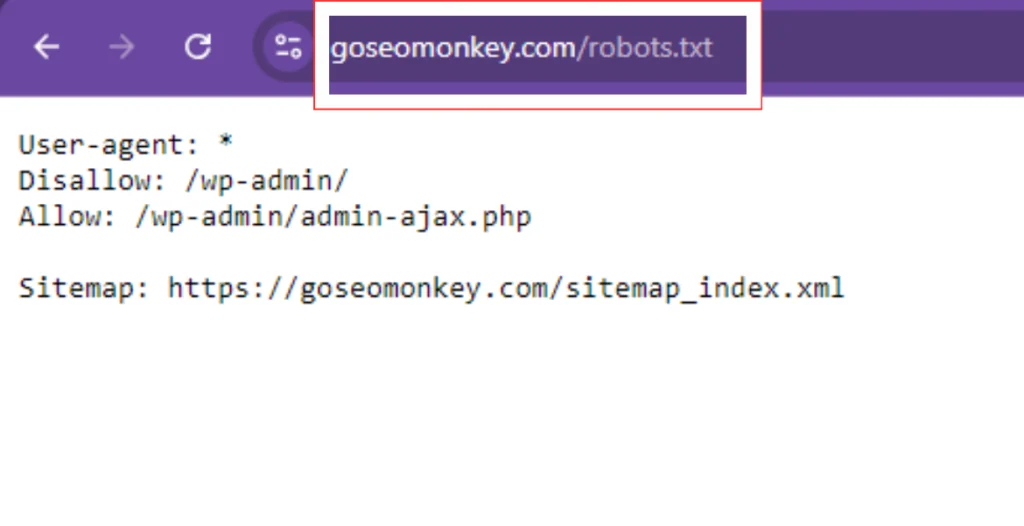
- Check Robots.txt: Ensure your robots.txt file does not block important pages. Access it by going to
yourwebsite.com/robots.txt.- Look for directives like
Disallow: /private/which may block crawlers.
- Look for directives like
- Review Meta Tags: Make sure your pages don’t have meta tags like <
meta name="robots" content="noindex"> that prevent indexing.
Create and Submit a Sitemap
- Generate a Sitemap: Use tools like XML-Sitemaps.com to create a sitemap of your site. Ensure it includes all important pages.
- Submit to Search Engines:
- For Google: Go to Google Search Console > Sitemaps > Add a new sitemap.
- For Bing: Go to Bing Webmaster Tools > Sitemaps > Submit a sitemap.
Common Crawlability Problems and How to Resolve Them
Crawlability issues can seriously impact your website’s visibility in search engines. Understanding why these problems occur and how to address them is crucial for maintaining a well-optimized site. Let’s dive deeply into common crawlability problems, their causes, and how to fix them effectively.
1. Broken Links
What are Broken Links? Broken links are hyperlinks that lead to pages that no longer exist or are unreachable. They can occur internally (within your site) or externally (leading to other sites).
Why They Occur:
- Deleted or Moved Pages: When pages are removed or moved without proper redirection.
- Typographical Errors: Mistakes in the URL when creating links.
- Server Issues: Problems with the server hosting the linked page.
How to Fix Broken Links:
- Identify Broken Links:
- Tools: Use tools like Screaming Frog, Ahrefs, or Broken Link Checker to find broken links.
- Google Search Console: Check the Coverage report for crawl errors related to broken links.
- Fix or Remove Links:
- Update Links: Correct the URL if it was mistyped or update it if the linked page has moved.
- Redirect: Implement 301 redirects from deleted pages to relevant existing pages.
- Regular Checks:
- Routine Audits: Periodically run link audits to ensure all links are functional.
2. Server Errors (5xx Errors)
What are Server Errors? Server errors occur when the server fails to fulfill a request. Common server errors include 500 (Internal Server Error), 502 (Bad Gateway), and 503 (Service Unavailable).
Why They Occur:
- Server Overload: High traffic or resource constraints can cause server failures.
- Configuration Errors: Incorrect server settings or misconfigured .htaccess files.
- Script Failures: Errors in server-side scripts or applications.

How to Fix Server Errors:
- Diagnose the Issue:
- Server Logs: Review server logs for error details.
- Error Reporting: Check for error messages and notifications from your hosting provider.
- Resolve Configuration Issues:
- Update Settings: Adjust server configuration settings to handle traffic and resource demands.
- Fix Scripts: Debug and correct issues in server-side scripts or applications.
- Monitor Server Health:
- Performance Monitoring: Use monitoring tools to track server performance and identify potential issues before they escalate.
3. Noindex Meta Tags
What are Noindex Meta Tags? Noindex meta tags are HTML tags used to instruct search engines not to index a specific page.
Why They Occur:
- Intentional Blocking: Pages might be marked noindex to prevent indexing of duplicate content or low-value pages.
- Accidental Implementation: Misplaced noindex tags can inadvertently block important pages.
How to Fix Noindex Meta Tags:
- Identify Pages with Noindex Tags:
- View Source Code: Check the HTML source code for
<meta name="robots" content="noindex">tags. - Google Search Console: Use the URL Inspection Tool to verify if pages are blocked by noindex tags.
- View Source Code: Check the HTML source code for
- Remove or Modify Tags:
- Update Meta Tags: Remove or adjust noindex tags on pages you want indexed.
- Verify Changes: Ensure that the changes are reflected by re-crawling the page using Google Search Console.
- Regular Review:
- Audit Meta Tags: Periodically review your site’s meta tags to ensure they align with your indexing goals.
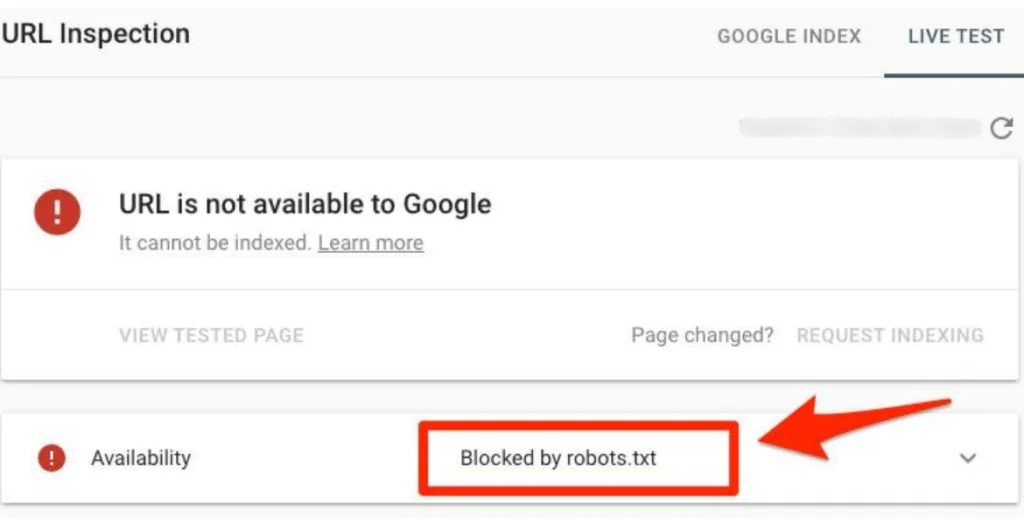
4. Robots.txt Issues
What are Robots.txt Issues? Robots.txt files instruct search engine crawlers on which pages or sections of your site they can or cannot access.
Why They Occur:
- Overly Restrictive Rules: Incorrectly configured robots.txt files can block important content from being crawled.
- Syntax Errors: Mistakes in the file’s syntax can lead to unintended blocking.
How to Fix Robots.txt Issues:
- Review Robots.txt File:
- Check Syntax: Ensure the syntax is correct and does not unintentionally block important pages.
- Test Directives: Use the robots.txt Tester in Google Search Console to validate your file.
- Update Robots.txt Rules:
- Adjust Allow/Disallow Directives: Modify directives to ensure critical pages are accessible to crawlers.
- Ensure Accessibility: Allow crawlers access to important directories and files.
- Monitor and Validate:
- Regular Testing: Periodically test your robots.txt file to ensure it functions as intended.
5. Duplicate Content
What is Duplicate Content? Duplicate content refers to identical or very similar content appearing on multiple pages or websites.
Why It Occurs:
- URL Variations: Different URLs leading to the same content (e.g., with or without trailing slashes).
- Content Scraping: Other sites copying your content without permission.
- Internal Duplication: Similar content appearing on different pages within your site.
How to Fix Duplicate Content:
- Identify Duplicate Content:
- Tools: Use tools like Copyscape or Siteliner to find duplicate content.
- Google Search Console: Check for duplicate content issues in the Coverage report.
- Address Duplication:
- Canonical Tags: Implement canonical tags to indicate the preferred version of a page.
- Content Revision: Rewrite or consolidate similar content to avoid duplication.
- Prevent Future Issues:
- URL Management: Use consistent URL structures and avoid unnecessary URL parameters.
- Monitor Content: Regularly check for duplicate content on your site and take action as needed.
Need Professional Content for your Website?
Our team of writers might be the perfect match for your requirements.
6. Page Load Speed
What is Page Load Speed? Page load speed is the time it takes for a web page to fully load and display content.
Why It Impacts Crawlability:
- Slow Load Times: Pages that load slowly can cause crawlers to time out or abandon the crawl.
- User Experience: Slow-loading pages negatively affect user experience and search engine rankings.
How to Improve Page Load Speed:
- Optimize Images:
- Compress Images: Use tools like TinyPNG or ImageOptim to reduce image file sizes without sacrificing quality.
- Use Proper Formats: Choose the right image formats (e.g., WebP for modern browsers).
- Minify CSS, JavaScript, and HTML:
- Remove Unnecessary Code: Minify and combine CSS and JavaScript files to reduce load times.
- Use Tools: Tools like UglifyJS for JavaScript and CSSNano for CSS can help with minification.
- Leverage Browser Caching:
- Set Expiry Dates: Configure your server to set expiry dates for static resources to improve load times on repeat visits.
- Enable Compression:
- Use Gzip or Brotli: Enable Gzip or Brotli compression to reduce the size of transferred files.
7. URL Parameters
What are URL Parameters? URL parameters are variables appended to the end of URLs, often used to track user sessions or filter content.
Why They Cause Problems:
- Duplicate Content: URL parameters can create multiple URLs with similar content, leading to duplicate content issues.
- Crawl Budget Waste: Crawlers may waste time on parameter-based URLs that don’t offer new content.
How to Manage URL Parameters:
- Canonical Tags:
- Set Canonical URLs: Use canonical tags to point search engines to the preferred version of a page.
- Use Google Search Console:
- Parameter Handling: Configure URL parameter handling in Google Search Console to avoid indexing issues.
- Clean URL Structure:
- Avoid Unnecessary Parameters: Simplify URLs and use clean, descriptive structures.
8. Thin Content
What is Thin Content? Thin content refers to pages with little or no valuable content, often resulting in low-quality or sparse information.
Why It Occurs:
- Lack of Depth: Pages with minimal text or substance.
- Automatically Generated Content: Content generated by automated tools without human review.
How to Fix Thin Content:
- Add Valuable Content:
- Expand Content: Provide comprehensive and relevant information on your pages.
- Include Multimedia: Use images, videos, and infographics to enhance content value.
- Remove or Merge Pages:
- Consolidate Thin Pages: Merge pages with similar topics into more comprehensive articles.
- Remove Low-Value Pages: Delete pages that offer little value and redirect them to more relevant content.
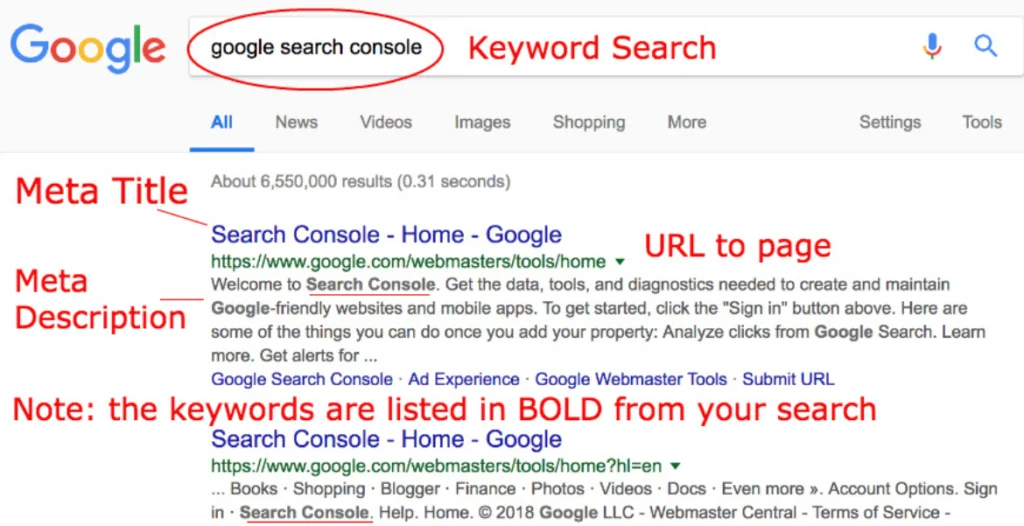
9. Incorrect or Missing Metadata
What is Metadata? Metadata includes elements like title tags, meta descriptions, and alt text for images.
Why It Matters:
- SEO Impact: Missing or incorrect metadata can affect how search engines understand and rank your pages.
- User Experience: Metadata helps users understand what a page is about before clicking through from search results.
How to Fix Metadata Issues:
- Optimize Title Tags:
- Unique Titles: Ensure each page has a unique and descriptive title tag (50-60 characters).
- Write Compelling Meta Descriptions:
- Engaging Descriptions: Create concise meta descriptions (150-160 characters) that encourage clicks.
- Use Alt Text for Images:
- Descriptive Alt Text: Provide descriptive alt text for images to improve accessibility and search engine understanding.
10. Access Restrictions
What are Access Restrictions? Access restrictions are settings that limit or block search engine crawlers from accessing certain parts of your site.
Why They Occur:
- IP Restrictions: Blocking based on IP addresses or user-agent strings.
- Authentication Barriers: Pages behind login screens or requiring authentication.
How to Fix Access Restrictions:
- Review Access Settings:
- Check IP Restrictions: Ensure no IP restrictions are inadvertently blocking crawlers.
- Allow Crawlers: Ensure pages requiring authentication are accessible or provide a way for crawlers to access them.
- Configure Authentication:
- Use Robots Meta Tags: Allow access to authenticated content if necessary using robots meta tags.
Set Up Access Restrictions
Make sure your site shows only what you want to show. We can help you out!
How to Request Google to Crawl Your Site
1. Google Search Console: Your Main Tool
Google Search Console (GSC) is the primary way to request Google to crawl your site. It offers tools to monitor, manage, and optimize your website’s performance in Google Search.
Setting Up Google Search Console
If you haven’t already, here’s how to set up GSC:
- Sign in to Google Search Console: Visit Google Search Console and log in with your Google account.
- Add Your Website: Click “Add Property” and enter your website URL.
- Verify Ownership: Google offers several ways to verify ownership, including:
- Uploading an HTML file to your site.
- Adding a meta tag to your site’s header.
- Connecting through your domain provider.
- Using Google Analytics or Google Tag Manager.
Once verified, you can start using the tools to monitor and improve your site’s crawling.
2. Submitting a New Sitemap
- Generate a Sitemap: Most content management systems (CMS) like WordPress automatically generate a sitemap. You can use plugins (e.g., Yoast SEO for WordPress) or online tools (like XML-sitemaps.com) to create one if needed.
- Locate the Sitemap URL: The sitemap is typically found at
yourwebsite.com/sitemap.xml. - Submit the Sitemap to GSC:
- Go to Google Search Console.
- On the left-hand side, click Sitemaps.
- Enter your sitemap URL (e.g.,
/sitemap.xml). - Click Submit.
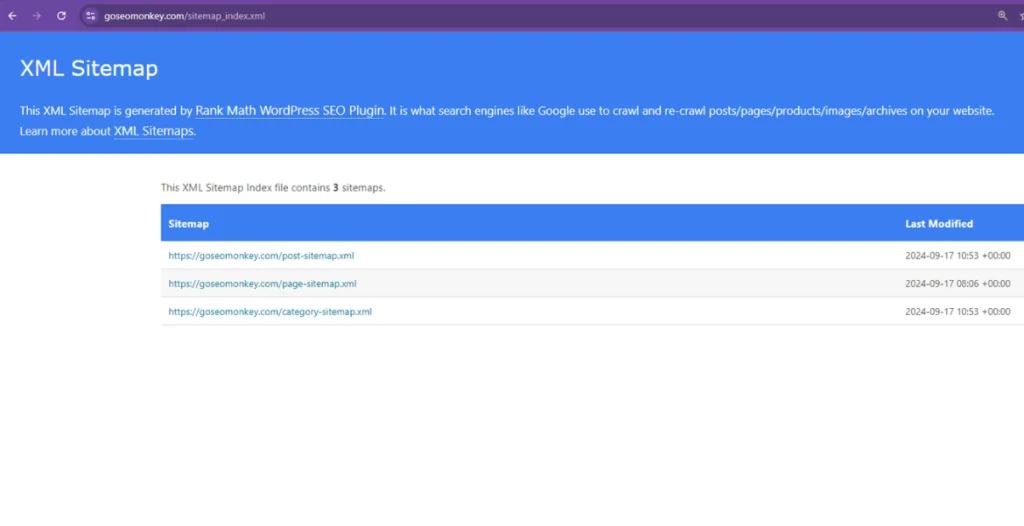
3. Using the URL Inspection Tool
The URL Inspection Tool in Google Search Console allows you to request Google to crawl or re-crawl specific pages. It’s particularly useful for individual page updates, bug fixes, or new content.
How to Use the URL Inspection Tool
- Log in to Google Search Console.
- Enter the URL: In the top search bar, paste the specific URL you want to be crawled (e.g., yourwebsite.com/new-page).
- View the URL’s Status:
- If the URL is already indexed, you’ll see the message “URL is on Google.”
- If it’s not indexed, you may see “URL is not on Google.”
- Request Indexing:
- If you want to prompt a re-crawl (even if the page is already indexed), click Request Indexing.
- Google will queue the URL for re-crawling. This process may take a few days, but it’s usually faster than waiting for Google’s automated crawlers.
When to Use the URL Inspection Tool
- New Pages: Whenever you publish new content, especially if it’s time-sensitive.
- Updated Content: For pages that have been significantly updated or corrected.
- Error Fixes: When you’ve resolved crawl errors or made improvements to the page.
4. Handling Large-Scale Changes
For significant changes, such as overhauling your site structure, updating your CMS, or migrating to a new domain, a more comprehensive crawl request may be necessary.
Steps for Large-Scale Crawling Requests
- Submit Updated Sitemap: If there’s been a major site change, update and resubmit your sitemap through Google Search Console.
- Check the Coverage Report: Go to Coverage in GSC to review errors, excluded pages, and valid URLs.
- Use Google’s Index Coverage API: If you manage a large website, this API allows you to programmatically request Google to crawl many URLs.
- Request a Site-Wide Crawl: For major site overhauls, submit the sitemap again, and monitor GSC for progress.
5. Avoiding Common Crawl Blockers
- What it Does: The
robots.txtfile tells search engine crawlers which pages they are allowed or not allowed to crawl. - Best Practice: Ensure that critical pages aren’t being blocked unintentionally. Use
AllowandDisallowdirectives carefully.- For example,
Disallow: /private/blocks crawlers from indexing your private directory.
- For example,
- Meta Tags: The
<meta name="robots" content="noindex">tag prevents crawlers from indexing a page. - Best Practice: Make sure this tag is not present on important pages you want Google to crawl and index.
- Redirect Loops: Ensure 301 or 302 redirects don’t result in redirect loops that confuse crawlers.
- Fix Broken Links: Regularly check for broken links using tools like Screaming Frog or Ahrefs.
Advanced Crawlability Techniques
- Disallow Directives: Use
Disallowto block crawlers from certain directories or pages you don’t want indexed. - Allow Directives: Ensure important pages are not blocked by
Disallowrules.
- Schema Markup: Add schema markup to your pages to provide additional information to search engines. Use tools like Google’s Structured Data Markup Helper.
Testing and Monitoring Your Site’s Crawlability
How to Perform a Crawlability Test
- Use Crawling Tools: Tools like Screaming Frog and Sitebulb can perform in-depth crawlability tests to identify issues.
- Analyze Reports: Review the test results for any crawl errors or issues.
Using Google Search Console for Monitoring
- Coverage Report: Regularly check the Coverage report to monitor which pages are being indexed and identify any errors.
- Performance Report: Use the Performance report to track how well your pages are performing in search results.
Resolving Recrawl Requests
How to Request Google to Reindex Your Site
- URL Inspection Tool: For specific pages, use the URL Inspection Tool in Google Search Console to request a reindex.
- Site-Wide Updates: For major site-wide changes, submit your updated sitemap to Google Search Console.
Handling Delays in Crawling and Indexing
- Patience: Crawling and indexing can take time. Check Search Console regularly for updates.
- Optimize Content: Ensure content is high-quality and relevant to encourage faster crawling and indexing.
Conclusion
Without crawling, your site’s content can go unnoticed, and all your hard work in creating engaging pages and valuable resources will be in vain. Whether you’re launching a new site, updating existing content, or fixing technical issues, making sure that Google crawls your site efficiently should be a top priority.
If navigating the complexities of SEO and Google crawling feels overwhelming, Go SEO Monkey is here to help. Our team specializes in optimizing your website for search engines, ensuring that your content gets the attention it deserves. From improving crawlability to fixing indexing issues, we handle it all.
FAQs
- How can I get my website on Google?
Submit your sitemap to Google Search Console and request indexing for better visibility. - What should I do if Google is not crawling my site?
Check your robots.txt file and meta tags, and use Google Search Console to request a crawl. - How often does Google crawl websites?
Crawling frequency depends on site authority and content updates. Regular updates can encourage more frequent crawling. - How do I fix crawl errors on my website?
Use Google Search Console to identify and fix errors promptly. - Can I request Google to recrawl my site?
Yes, use the URL Inspection Tool in Google Search Console to request reindexing or recrawling.



