
Table of Contents
ToggleCrawlability refers to the ability of search engine crawlers, like Googlebot, to access and navigate through all the pages of a website. If your site’s pages are easily crawlable, search engines can find and index them for users to discover through search results.
However, if certain parts of your website are hard to reach or blocked, they won’t show up on Google. Essentially, if your website isn’t crawlable, it won’t rank.
What Are Crawlers in SEO?
Crawlers, sometimes referred to as bots or spiders, are programs used by search engines to “crawl” or scan websites.
These crawlers travel through a site by following links from one page to another, collecting data and reporting it back to the search engine. This process is key for search engines to understand your website’s content and determine where it should appear in search results.
What is Crawling in SEO?
Crawling in SEO is the first step in the search engine’s process of discovering and indexing pages. When a crawler lands on your site, it moves from page to page by following hyperlinks, gathering data along the way.
The crawler reports the data back to the search engine, where it is processed and indexed for future use in search results.
How Does Crawlability Work?
Crawlability works through search engine crawlers that systematically visit your site and scan through each page. The crawler reads the HTML code, looks for crawlable links, and navigates the site’s structure. If it encounters a page that’s hard to reach or blocked (e.g., by a robots.txt file), it will skip that part of the site, which could hurt your SEO.
After crawling, the next step is indexing, where the search engine stores information from the crawled pages in its massive database. Only indexed pages can show up in search results, which is why improving crawlability is crucial.
Website Not Getting Crawled?
We offer complete site audits to identify areas for improvement.
Why Is Crawlability Important for SEO?
Crawlability is one of the foundational elements of good SEO. Without it, no matter how optimized your keywords are or how valuable your content is, search engines simply won’t find your pages. Poor crawlability can result in lower rankings or certain pages not appearing in search results at all.
For example, if a site has broken links or redirects that confuse the crawler, it might not fully crawl the site, leading to missed opportunities for ranking.
Common Crawlability Problems
Crawlability problems occur when search engines can’t effectively access or navigate a website, leading to parts of the site not being indexed or ranked. Here are the most common crawlability problems:
1. Crawl Errors
- Crawl Errors
Crawl errors arise when search engines try to access a page but fail due to issues like server errors (5xx), broken links, or missing pages (404 errors). These errors prevent search engines from fully crawling the website, resulting in pages not being indexed.

- Crawl Budget Issues
Each website has a crawl budget, which is the number of pages search engines will crawl within a certain period. If a website has too many pages, redirects, or unnecessary content (like duplicate pages), the crawl budget can be wasted on low-value pages, causing important pages to be skipped.
- Non-Crawlable Pages
Pages blocked by the robots.txt file or meta tags (noindex, nofollow) may prevent search engines from accessing them. This often happens when site owners mistakenly block important pages or entire sections of their website.
- Blocked Resources
CSS, JavaScript, or images blocked by robots.txt files can hinder search engines from fully understanding how your website works, leading to poor crawlability. If key resources are blocked, crawlers might misinterpret the page layout or functionality.
- Broken Links
Broken links (those leading to 404 error pages) interrupt the crawling process by leading search engines to dead ends. This not only wastes crawl budget but also negatively impacts user experience and SEO rankings.
- Excessive Redirects
Too many redirects, especially redirect chains or loops, confuse search engines and limit crawlability. Crawlers may give up after encountering too many redirects, skipping important pages in the process.
- Duplicate Content
Duplicate content confuses search engines as they struggle to identify the original source. This can lead to crawl inefficiency, where crawlers waste time on redundant pages, missing out on more important, unique content.
- Slow Page Load Times
Pages that load slowly reduce crawl efficiency. Crawlers are programmed to spend a limited amount of time on each site, and slow pages might limit how many pages get crawled during a visit.
How to Check Crawled Pages
To assess your site’s crawlability, you can use various tools like Google Search Console, Screaming Frog, or Ahrefs. These tools provide a crawlability test, giving you insight into any potential issues like broken links, missing pages, or blocked resources.
Crawlability Test Examples:
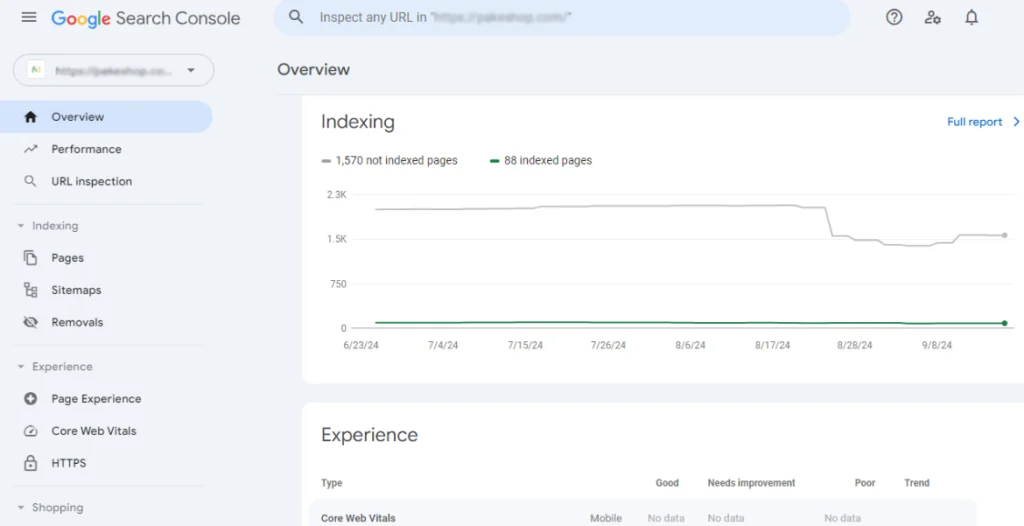
- Google Search Console: Run a coverage report to see which pages are being crawled and indexed.
- Screaming Frog: Conduct a crawl analysis to check for errors like broken links or missing meta tags.
How to Improve Crawlability
Improving crawlability ensures that search engines can easily access and index all the important pages of your website. Here are some actionable steps to enhance your site’s crawlability:
- Optimize Internal Linking
Create a clear, logical internal linking structure that connects all the important pages on your site. Use relevant anchor text and make sure there are no orphaned pages (pages with no links pointing to them). Internal links guide crawlers through your site and help them discover new content.
- Fix Broken Links
Broken links (those that lead to 404 errors) can disrupt crawlers, wasting crawl budget and leaving important pages unvisited. Regularly audit your website for broken links using tools like Google Search Console or Screaming Frog, and fix or remove them promptly.
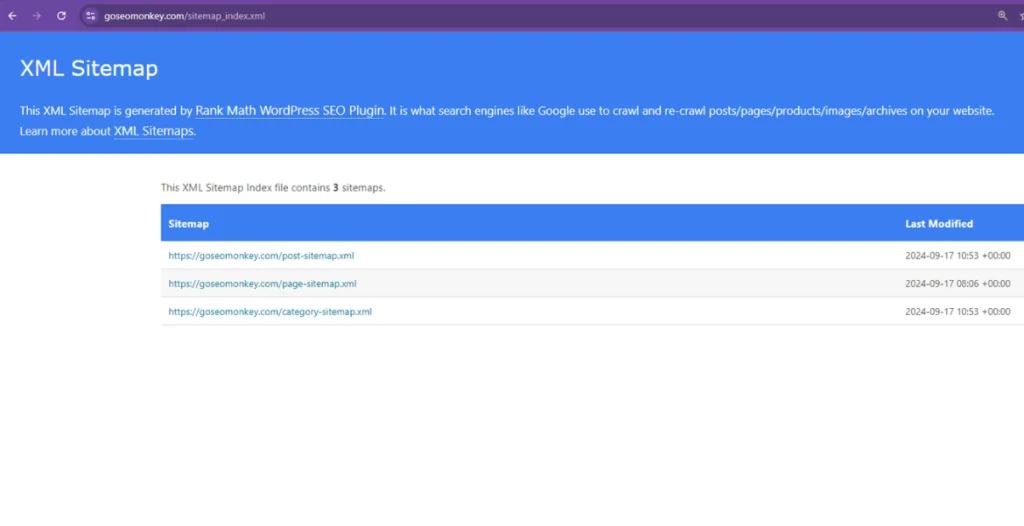
- Create and Submit an XML Sitemap
An XML sitemap acts as a roadmap for search engines, listing all the important pages you want crawled and indexed. Make sure your sitemap is up to date and submit it through Google Search Console to ensure search engines know which pages to prioritize.
- Improve Site Speed
Faster sites are crawled more efficiently. Optimize your site’s loading speed by compressing images, minifying CSS and JavaScript files, and using a content delivery network (CDN). Tools like Google PageSpeed Insights can help identify areas for improvement.
- Use Robots.txt Correctly
Ensure your robots.txt file is properly configured to allow search engines to crawl important sections of your site. Avoid blocking essential resources like images, CSS, or JavaScript files, which are necessary for crawlers to understand the full context of your pages.
- Implement Canonical Tags
Canonical tags help search engines understand which version of a page is the original, especially in cases of duplicate or similar content. This prevents crawl budget from being wasted on duplicate pages and ensures crawlers focus on the right pages.
- Ensure Mobile-Friendliness
With mobile-first indexing, Google primarily uses the mobile version of your website for crawling and indexing. Ensure your website is responsive and works well on mobile devices. A mobile-friendly site improves crawlability and overall SEO performance.
- Avoid Excessive Redirects
Too many redirects, especially redirect chains or loops, can confuse crawlers and prevent them from reaching important content. Minimize the number of redirects by keeping your URL structure simple and avoiding unnecessary changes.
- Minimize Crawl Budget Waste
Avoid wasting your crawl budget on low-value pages like duplicate content, thin content, or pages with little SEO importance. Use noindex tags on these pages to prevent search engines from crawling them, allowing more crawl budget for high-value content.
- Use Structured Data
Implementing structured data (schema markup) helps search engines better understand your content. While it doesn’t directly affect crawlability, structured data makes your pages more attractive for search engines, encouraging more thorough crawling.
- Regularly Audit Your Site
Conduct regular technical audits of your website using tools like Google Search Console, Ahrefs, or SEMrush. These tools can help you identify crawl errors, duplicate content, and other issues that could affect crawlability.
- Reduce Page Load Depth
Make sure that important pages are accessible within a few clicks from the homepage. Pages buried deep within the site structure (more than 3-4 clicks away) may not be crawled as frequently, reducing their visibility in search results.
Need Help Optimizing your Website?
Our expert organic SEO team might be the perfect match for your requirements.
Conclusion
Crawlability is the cornerstone of any successful SEO strategy. By optimizing crawlability, you ensure that search engines can properly access, read, and index your website’s content.
Regular audits, optimizing internal links, and fixing crawl errors are essential steps in maintaining a crawlable site. If you need help optimizing your website for crawlability, Go SEO Monkey offers expert services to ensure your site gets the visibility it deserves.
FAQs
- What is crawlability?
Crawlability refers to how easily search engine crawlers can access and index the pages on your website. - How can I improve the crawlability of my website?
You can improve crawlability by fixing broken links, optimizing internal linking, creating an XML sitemap, and ensuring your pages load quickly. - Why is my website not being crawled by search engines?
This could be due to crawlability issues like blocked resources, broken links, or errors in your robots.txt file. - How does robots.txt affect crawlability?
The robots.txt file controls which parts of your site search engines can access. Incorrect settings can block important pages from being crawled. - Can crawlability issues hurt my rankings?
Yes, if search engines can’t crawl your site, your content won’t appear in search results, which can hurt your rankings.



